Quora is a question-and-answer site. You can view all my contributions here; selected highlights are listed below. I encourage you to check out the other answers submitted for each question, too!
Advances in epigenetics mean incredibly detailed profiles of criminal suspects might soon be reality. Is the legal system ready to use this information?
Picture the scene. A detective is addressing her team:
“The DNA test results are in. We’re looking for a white male suspect, 34–37 years old, born in the summer in a temperate climate. He’s used cocaine in the past. His mother smoked, but he doesn’t. He drinks heavily, like his Dad. We’re seeing high stress levels, and looking at the air pollution markers, let’s start looking downtown, probably near a major intersection”.
Science fiction? Yes, for now. But advances in epigenetics – the study of reversible chemical modifications to chromosomes that play a role in determining which genes are activated in which cells – might soon start making their way out of research labs and into criminal forensics facilities.
Take the idea of the epigenetic clock, one of the ways in which our cells and DNA can betray our age. Epigenetic patterns change throughout our lives, along broadly predictable paths, making it possible to infer age from DNA samples.
Steve Horvath at UCLA has developed a statistical model based on 350 potential epigenetic modification positions in the human genome that can estimate your age to within three and a half years. The rate of epigenetic aging seems to depend somewhat on race, and can be affected by some health conditions, but this kind of test is already at the stage when forensics labs are validating it for use in criminal investigations.
The things we get up to while our epigenetic clocks are ticking can also leave their mark on our DNA. Cigarette smoking correlates with characteristic and persistent epigenetic changes. The same goes for cocaine, opioids and other illicit substances. There’s also some evidence for epigenetic signatures of obesity, traumatic childhood experiences, exposure to tobacco in the womb, season of birth, exposure to environmental pollution, exercise, and possibly even the things our parents and grandparents did before we were born.
Quora is a question-and-answer site. You can view all my contributions here; selected highlights are listed below. I encourage you to check out the other answers submitted for each question, too!
Friendly fire: while the immune system tries to protect us from viruses, it could be causing cancer
The immune system is a fickle thing, both hero and villain.
The ability of our ancestors to survive plague and pestilence was one of the forces that shaped the evolution of the human species into its current form. But many of us now find ourselves in environments where many of the biggest infectious threats have been neutralised by a combination of vaccination programmes, improved hygiene, and (temporarily) effective treatments. With their usual duties cut back so drastically, our evolutionary superstar immune systems sometimes lash out at innocuous perceived threats. This can cause allergies, multiple sclerosis, and other auto-immune disorders in the process – sins of commission, if you will.
But at least our immune systems are still pretty good at protecting us from infections and most cancers, right?
Well, much of the time, yes. The importance of the immune system in protecting us from cancer is evident from the increased rates of the disease in people with reduced immunity due to HIV/Aids or followingorgan transplants. And yet the immune system’s sins of omission mean that far too many cancer cells slip through the net – and we still get colds and the dreaded norovirus, too.
This week, though, new research from University College London (UCL) suggests for the first time that the immune system also commits sins of commission when it comes to cancer.
The research, published in the journal Cell Reports on Thursday, concerns a class of genes called the APOBEC family. These genes code for proteins that attack invading viruses by mutating their DNA, a tactic that can stop or at least slow the replication and spread of the virus. The mutations caused by APOBEC proteins occur in a characteristic pattern – a pattern that also shows up in some types of cancer, including types that are often caused by infection with human papilloma viruses (HPV). Could the mutations in these cancers be caused by misfiring antiviral defences?
Human papilloma virus. Photograph: Laboratory of Tumor Virus Biology/Wikimedia Commons
Drs Stephen Henderson, Tim Fenton and their teams at UCL have now demonstrated that there is indeed an association between the presence of HPV in some cancer cells, elevated activity of the APOBEC proteins in those cells, and the presence of the characteristic APOBEC-mediated mutation pattern. These findings support the idea that HPV infection triggers an anti-viral attack that not only hits the intended target – the viral genes –but also the cell’s own DNA. The UCL team also found that mutations caused by APOBEC have a strong tendency to hit genes such as PIK3CA that help to regulate the growth and division of the cell, and whose mutation is associated with the development of cancer.
“It is not clear why HPV infection causes the APOBEC genes to misbehave and mutate PIK3CA,”says Dr Henderson. “It could be that the body responds to HPV infection with increased ABOBEC activity, simply making ‘friendly fire’ more likely. Alternatively, there may well be something about the virus that causes the APOBEC response to wrongly target the body’s own genes for mutation.”
The good news is that these new findings open up new avenues for researchers working on diverse aspects of the cancer problem: there are known inherited variations in a member of the APOBEC family that have been linked with an elevated risk of developing breast cancer; other viral infections may also be associated with cancer, possibly via the same mechanism; and drugs that target mutated versions of the PIK3CA protein are already being developed.
Meanwhile, if you don’t want to give your trigger-happy immune system a shot at the human papilloma virus, effective vaccines are now available.
The word ‘epigenetics’ is everywhere these days, from academic journals and popular science articles to ads touting miracle cures. But what is epigenetics, and why is it so important?
Epigenetics is one of the hottest fields in the life sciences. It’s a phenomenon with wide-ranging, powerful effects on many aspects of biology, and enormous potential in human medicine. As such, its ability to fill in some of the gaps in our scientific knowledge is mentioned everywhere from academic journals to the mainstream media to some of the less scientifically rigorous corners of the Internet.
But what exactly is epigenetics – and does the reality live up to the hype?
The incidence of the word ‘epigenetics’ in published books, 1800-2008, via Google ngrams. Bringing this graph up to date and including other publication types would send that line right off the top of your screen.
Epigenetics is essentially additional information layered on top of the sequence of letters (strings of molecules called A, C, G, and T) that makes up DNA.
If you consider a DNA sequence as the text of an instruction manual that explains how to make a human body, epigenetics is as if someone’s taken a pack of highlighters and used different colours to mark up different parts of the text in different ways. For example, someone might use a pink highlighter to mark parts of the text that need to be read the most carefully, and a blue highlighter to mark parts that aren’t as important.
There are different types of epigenetic marks, and each one tells the proteins in the cell to process those parts of the DNA in certain ways. For example, DNA can be tagged with tiny molecules called methyl groups that stick to some of its C letters. There are proteins that specifically seek out and bind to these methylated areas, and shut it down so that the genes in that region are inactivated in that cell. So methylation is like a blue highlighter telling the cell “you don’t need to know about this section right now.”
DNA doesn’t just float around the cell by itself; it wraps itself around a group of proteins called histones. There are some epigenetic marks that actually affect these histones, rather than the DNA itself.
The DNA double helix wrapped around four histone proteins, in a structure called a nucleosome. By Richard Wheeler (Zephyris) [CC-BY-SA-3.0]]/Wikimedia Commons
Methyl groups and other small molecular tags can attach to different locations on the histone proteins, each one having a different effect. Some tags in some locations loosen the attachment between the DNA and the histone, making the DNA more accessible to the proteins that are responsible for activating the genes in that region; this is like a pink highlighter telling the cell “hey, this part’s important”. Other tags in other locations do the opposite, or attract other proteins with other specific functions. There are epigenetic marks that cluster around the start points of genes; there are marks that cover long stretches of DNA, and others that affect much shorter regions; there are even epigenetic modifications of RNA, a whole new field that I’m simultaneously fascinated by and trying to ignore because it’s bound to create a lot of extra work for me in both the project manager and the grant writing parts of my role. There are no doubt many other marks we don’t even know about yet.
Even though every cell in your body starts off with the same DNA sequence, give or take a couple of letters here and there, the text has different patterns of highlighting in different types of cell – a liver cell doesn’t need to follow the same parts of the instruction manual as a brain cell. But the really interesting thing about epigenetics is that the marks aren’t fixed in the same way the DNA sequence is: some of them can change throughout your lifetime, and in response to outside influences. Some can even be inherited, just like some highlighting still shows up when text is photocopied.
Epigenetics and our experiences
Any outside stimulus that can be detected by the body has the potential to cause epigenetic modifications. It’s not yet clear exactly which exposures affect which epigenetic marks, nor what the mechanisms and downstream effects are, but there are a number of quite well characterized examples, from chemicals to lifestyle factors to lived experiences:
Bisphenol A (BPA) is an additive in some plastics that has been linked to cancer and other diseases and has already been removed from consumer products in some countries. BPA seems to exert its effects through a number of mechanisms, including epigenetic modification.
Childhood abuse and other forms of early trauma also seem toaffect DNA methylation patterns, which may help to explain the poor health that many victims of such abuse face throughout adulthood.
Epigenetic inheritance
This is an area where the hype has advanced faster and further than the actual science. There have been some fascinating early studies on the inheritance of epigenetic marks, but most of the strongest evidence so far comes from research done on mice. There have been hints that some of these findings also apply to human inheritance, but we’ve only just started to untangle this phenomenon.
We’ve known for some time that certain environmental factors experienced by adult mice can be passed on to their offspring via epigenetic mechanisms. The best example is a gene called agouti, which is methylated in normal brown mice. However, mice with an unmethylated agouti gene are yellow and obese, despite beinggenetically essentially identical to their skinny brown relatives. Altering the pregnant mother’s diet can modify the ratio of brown to yellow offspring: folic acid results in more brown pups, while BPAresults in more yellow pups.
Research on the epigenetic inheritance of addictive behavior is less advanced, but does look quite promising. Studies in rats recently demonstrated that exposure to THC (the active compound in cannabis) during adolescence can prime future offspring to display signs of predisposition to heroin addiction.
Studies of humans whose ancestors survived through periods ofstarvation in Sweden and the Netherlands suggest that the effects of famine on epigenetics and health can pass through at least three generations. Nutrient deprivation in a recent ancestor seems to prime the body for diabetes and cardiovascular problems, a response that may have evolved to mitigate the effects of any future famines in the same geographic area.
“More research is needed”
Epigenetics research continues apace in labs investigating a dazzling variety of topics. One interesting direction is the application of high-throughput sequencing technologies to the characterization of hundreds of ‘epigenomes’ (epigenetic marks across the entire genome). I manage a project that’s part of the International Human Epigenomics Consortium (IHEC), and am also a member of a couple of the consortium’s working groups, so I see for myself every day how fast this field is progressing. The goal of IHEC is to generate at least 1,000 publicly available ‘reference’ epigenomes (patterns of DNA methylation, six histone modifications, and gene activation) from various normal and diseased cell types. These references will serve as a baseline in other studies, in the same way that the original human genome project sequenced a reference genome to which scientists can now compare their own results to identify changes associated with specific diseases.
This is a field that’s guaranteed to keep generating headlines and catching the public’s interest. The apparent ability of epigenetics to fill some pretty diverse gaps in our understanding of human health and disease, and to provide scientific mechanisms for so many of our lived experiences, makes it very compelling, but we do need to be careful not to over-interpret the evidence we’ve collected so far. And we certainly need to be highly sceptical of anyone claiming that we can consciously change our epigenomes in specific ways through the power of thought.
Now that I’ve piqued your interest in this fascinating field (and maybe that of your unborn children. Epigenetics!), in my next piece I’ll explore the role of epigenetic changes in the onset of cancer and other diseases, and what this means for the development of new treatment options.
There are links to videos and other resources about epigenetics on the IHEC website. There’s also a free Massive Open Online Course (MOOC) in epigenetics offered by the University of Melbourne on the Coursera site; I just started the April 2014 session so I can vet it for work-related purposes and it’s great so far, although a pretty solid background in genetics is required.
In the 2000 M Night Shyamalan film Unbreakable, Samuel L Jackson’s character – a man born with a severe form of brittle bone disease – asks Bruce Willis’s character, ‘if there is someone like me in the world, and I am at one end of the spectrum, couldn’t there be someone else, the opposite of me at the other end? Someone who doesn’t get sick, who doesn’t get hurt like the rest of us?’ Some cancer researchers are trying to answer the same question; however, in real life, it’s just not that easy to unmask a superhero
In June 2013, I described how sequencing the highly abnormal genomes of cancer cells can identify some of the mutations that drive the progress of the disease (and how that’s only the beginning of the story). In the discussion that ensued, reader BlueSky3 commented:
Hope more likely rests in examining the control systems/defence mechanisms of those carrying a hereditary cancer fault which has perhaps persisted in evolutionary time. Not all mutation carriers succumb. Why not?
This comment was so interesting that it’s been percolating at the back of my brain for months. We know that women who inherit a faulty copy of the BRCA1 or BRCA2 gene have a highly elevated risk of developing breast or ovarian cancer – but cancer is not an inevitability. We also know that smokers have a highly elevated risk of developing lung, throat, or oral cancer – but some of them don’t. Why?
The answer lies in the complexity of cancer. The first mutation that starts the first abnormal cell down its path to malignancy can be caused by any number of factors: genetic predisposition, radiation, chemical agents, viruses. Similarly, any number of factors can influence the direction the disease travels thereafter. The first mutated cell has to escape everything the body can throw at it – DNA repair, the shutdown of cell division, programmed cell death, the immune system – before it can become truly dangerous. This complexity creates a number of possible points of intervention. Many, especially those related to the health of the immune system, are at least partially related to lifestyle factors, but in this article I’m going to focus on natural-born superheroes only – that is, those who inherit genetic factors that protect them from cancer.
Unusual suspects
The suggestion to study people with known cancer predisposition mutations who don’t go on to develop cancer is a great one, but not an easy one. If someone is unaware they have such a mutation, and they remain healthy, doctors and researchers have no way to identify them as a subject of interest. Additionally, many people who do know they have such a mutation can now take preventive measures (such as Angelina Jolie’s recent pre-emptive double mastectomy upon learning her BRCA gene mutation status), and we have no way of knowing whether they would have gone on to develop cancer if these measures had not been taken. All this adds up to a very small sample size to study, which makes the identification of subtle genetic correlations extremely difficult. It is possible, however, to search for “superhero” genes among the much larger general population, and to relate some of the findings back to more specialised populations such as those with inherited mutations in BRCA and other cancer susceptibility genes.
Finding Superman
Many years ago, I attended a seminar by local researcher Michael Hayden about using very rare genetic disorders on one end of a spectrum to find new ways to fight very common disorders at the other end of the same spectrum. For instance, Hayden learned of a family with an inherited inability to feel pain, and was able to identify the faulty protein responsible; his lab recently published the results of a preliminary trial of a drug that targets the same protein in people without the disorder, and that may represent an entirely new class of painkillers.)
Unfortunately, finding people with genetic protection from cancer isn’t this straightforward. A person with no ability to feel pain will come to the attention of the medical profession early in life, when they walk for a week on a broken bone or show some other outward sign of their mutation. However, someone with an unusual degree of genetic protection from cancer is unlikely to present in the same way, making it harder to identify the relevant gene variants and to extrapolate from this knowledge to find a way to help prevent cancer in others.
Scientists are a resourceful bunch, though, and we’re starting to make progress despite these limitations. One approach is to look for protective gene variants in the general population, by comparing the gene sequences of people with cancer to those of healthy controls of comparable age and with similar risk factors. For example, in 2004 Angela Cox’s group at the University of Sheffield looked for correlations between breast cancer and the sequences of genes involved in programmed cell death. (This process, also known as apoptosis, is one of the body’s defence mechanisms that a cancer cell must evade if it is to go on to form a tumour. Apoptosis can be triggered by a number of different signalling pathways, each with multiple components; see the diagram for part of the picture.)
One of many apoptosis signalling pathways. Figure uploaded by:Subclavian/Wikipedia
Cox’s team found that women who’d inherited a variant called D302H in the apoptosis-related CASP8 gene were less likely to develop breast cancer. This variant has since been shown to correlate with a reduced risk of prostate and other cancers, and in 2010 the Group for Assessment of Hereditary Cancer of Valencia Community reported that “CASP8 D302H polymorphism delays the age of onset of breast cancer in BRCA1 and BRCA2 carriers” – making its carriers not unbreakable, but definitely less fragile than the rest of us.
Like so many others, recent technology advances mean that this field of research is now dominated by large-scale whole-genome studies. In 2013, a major European cancer genetics consortium called COGS(Collaborative Oncological Gene-environment Study) published a series of papers describing the results of a massive genome-wide association study of 100,000 cancer patients and 100,000 healthy controls. The study was designed to identify genetic variants that affect the risk of developing hormonally mediated (ie breast, ovarian and prostate) cancers. As expected, most genetic variants were found to increase the risk of cancer, but a few protective variants were also identified. For example, a variant in a component of the telomerase enzyme, which repairs the protective cap structures at the end of chromosomes, correlated with longer caps and reduced risk of some forms of breast cancer, including BRCA-related breast cancer.
The power of whole genome sequencing is also being applied to the study of people of advanced age who’ve avoided the most common causes of death, including cancer. There are a number of “super-ager” studies of this kind under way, including one at my organisation (I’m not involved with the project in any way, but I hear about it in meetings and in conversations at the pub after work). Dr Angela Brooks-Wilson leads the study, which involves sequencing the genomes of people aged 85 or older who are in good health, and who’ve never been diagnosed with cancer, heart disease, stroke, pulmonary disease, diabetes, or Alzheimer’s disease. It’s early days still, but hopes are high.
Back in June, reader BlueSky3 continued:
We are spending millions on dissecting the ‘cancer genome’ in minute detail and on genome wide association studies, shame a bit of the research money cannot be diverted to genetically dissecting the differences between mutation carriers living into their nineties and their less fortunate relatives who succumb to cancer in their thirties
I hope this article has demonstrated that we are in fact making some progress in this direction. We haven’t found our superhero, and I have no last-minute plot twist up my sleeve – but labs full of everyday heroes are on the case, and this story is bound to have many sequels over the years.

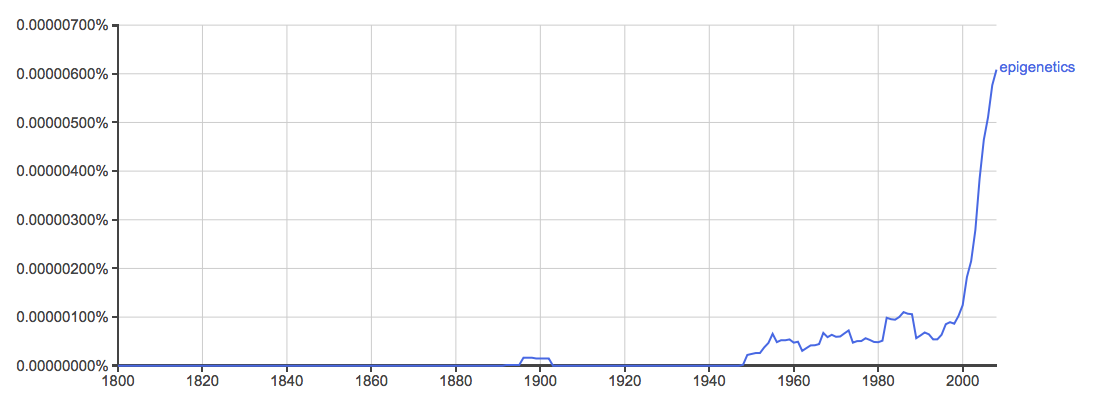




{kind=link}